



本カンパニー異動前に所属していた案件ではデータ抽出関連でSQLを書くことが多々ありました。
膨大なデータを加工、抽出する作業が頻繁に飛んでくるため、ただ正確な結果を出すだけでなくレビューの際の可読性や速度を意識したSQL作成が重要になることも多々ありました。
しかし、開発環境の都合上EXPLAIN ANALYZEを実行することができず、どの程度速度向上の面で効果があるのかを検証することができませんでした。
そこで当時「このポイントを意識すれば速度が向上する!」と思っていたことについて、実際にどの程度効果があるのかを検証してみました。
検証用の環境構築に関すること
dockerにて環境を構築。
(本記事は速度検証がメインのため、詳細は割愛します)
DB:PostgreSQL 14
接続ツール:pg Admin4
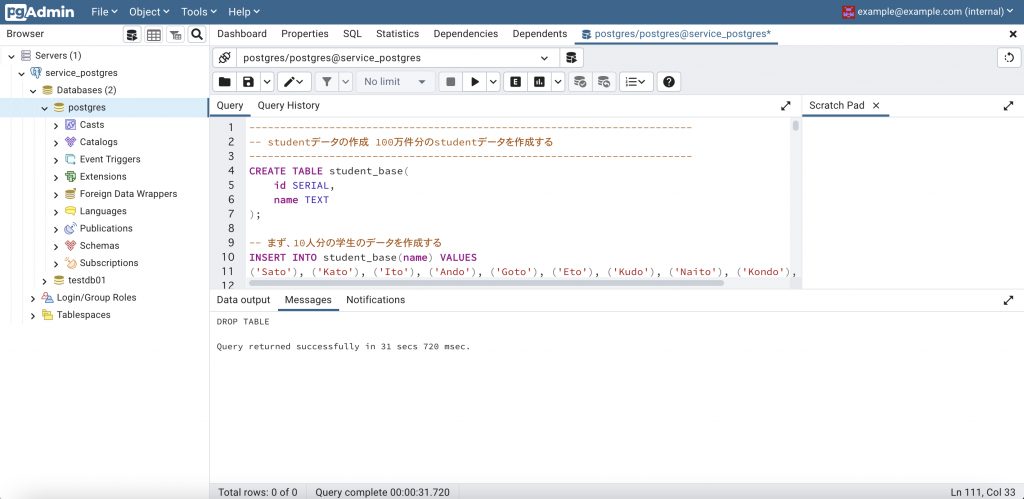
検証用環境を構築する
dockerで構築した環境に、pg Adminでログイン。
操作画面
以下のSQLを実行し、テストデータを作成します。
コメントでどのようにデータを大量に生成しているかを記載していますが、イメージしにくい場合は実際にSQLを動かして確認するのがよろしいと思います。
------------------------------------------------------------------------
-- studentデータの作成 100万件分のstudentデータを作成する
------------------------------------------------------------------------
CREATE TABLE student_base(
id SERIAL,
name TEXT
);
-- まず、10人分の学生のデータを作成する
INSERT INTO student_base(name) VALUES
('Sato'), ('Kato'), ('Ito'), ('Ando'), ('Goto'), ('Eto'), ('Kudo'), ('Naito'), ('Kondo'), ('Endo');
CREATE TABLE student(
id SERIAL,
name TEXT,
PRIMARY KEY(id)
);
-- student_baseをクロス結合し、その結果をstudentテーブルに投入する
-- student_base自体は10件だが、6テーブルクロス結合することで、10^6=100万件のデータができる
INSERT INTO student(
id,
name
)
SELECT
ROW_NUMBER() OVER() AS id,
s1.name || cast(ROW_NUMBER() OVER() AS TEXT) AS name
FROM
student_base AS s1,
student_base AS s2,
student_base AS s3,
student_base AS s4,
student_base AS s5,
student_base AS s6;
------------------------------------------------------------------------
-- 科目データを作成する
------------------------------------------------------------------------
CREATE TABLE subject(
id SERIAL,
name text,
PRIMARY KEY(id)
);
INSERT INTO subject(name) VALUES
('数学'), ('化学'), ('生物'), ('地理'), ('英語'), ('国語');
------------------------------------------------------------------------
-- 600万件分のscoreデータを作成する
------------------------------------------------------------------------
-- まず、10人分の学生用の得点データを作成する
CREATE TABLE score_base(
id SERIAL,
student_id INTEGER ,
subject_id INTEGER DEFAULT 0,
PRIMARY KEY(id)
);
INSERT INTO score_base(student_id) VALUES
(1),(2),(3),(4),(5),(6),(7),(8),(9),(10);
-- score_baseをクロス結合し、100万件分作成する
-- さらに、その結果をsubjectテーブルともクロス結合し、その結果をstudentテーブルに投入する
-- 100万人の学生の、各科目の得点データが作成されるので、10^6 * 6=600万件のデータができる
CREATE TABLE score(
id SERIAL,
student_id integer,
subject_id integer,
score integer,
PRIMARY KEY(id)
-- FOREIGN KEY(student_id)
-- REFERENCES student(id),
-- FOREIGN KEY(subject_id)
-- REFERENCES subject(id)
-- 検証の関係でstudent,subjectテーブルには外部キーを設定しない(後述)
);
INSERT INTO score(student_id, subject_id, score)
SELECT
student_id,
round(
(random() * (1 - 12))::numeric,
0
) + 12 AS subject_id, --subject_idには1-12のランダム値を入れる
round(
(random() * (1 - 100))::numeric,
0
) + 100 AS score
FROM
(
SELECT
ROW_NUMBER() OVER() AS id,
ROW_NUMBER() OVER() AS student_id
FROM
score_base AS s1,
score_base AS s2,
score_base AS s3,
score_base AS s4,
score_base AS s5,
score_base AS s6
) AS data_table,
subject;
-- 検証用にスコアを一部削除
DELETE FROM student
WHERE id >= 199000 AND id < 200000;
DELETE FROM score
WHERE id >= 5900000;
-- 不要なテーブルを削除する
DROP TABLE IF EXISTS student_base;
DROP TABLE IF EXISTS score_base;上記のSQLを実行すると以下のテーブルができます。
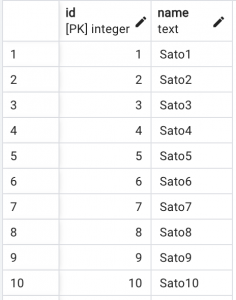
- studentテーブル(99.9万件)
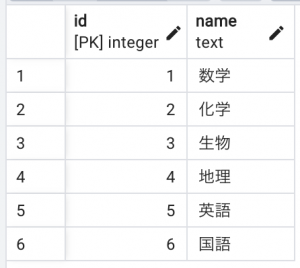
- subjectテーブル(6件)
- scoreテーブル(590万件)
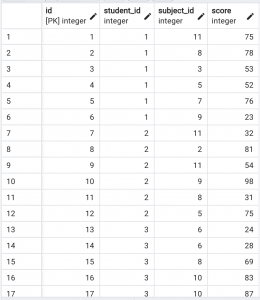
scoreテーブルには各学生の科目ごとの得点が入っています。
これらのテーブルを結合集計するSQLを作成し、昔実装時に意識していたポイントの有無によってどのぐらい実行時間に差が出てくるのかを調べてみます。
結合集計の際の条件は、以下の通りです。
- studentテーブルと、scoreテーブルに両方データが存在すること
- 結合キーはstudent.idと、score.student_idです。
- わざとscoreテーブルとstudentテーブルからデータを一部消しています。集計時に片方のテーブルにのみ存在するデータを作るためです。
- scoreテーブルにのみ存在し、studentテーブルに存在しないデータを作れるようにするために、外部キー設定を入れていません。
- scoreテーブルのsubject_idが、subjectテーブルのidに存在すること
- 結合キーはsubject.idと、score.subject_idです。
- scoreテーブルに存在し、subjectテーブルに存在しないデータを作るために、score.subject_idには1-12の数値をランダムに入れるようにしています。
- そのため、外部キー設定を入れていません。
実行結果
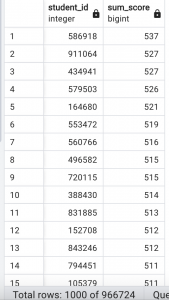
ばらつきを考慮して各5回実行した結果を載せています。
また、キャッシュを考慮して初回実行の結果は計算対象外としています。
1.通常のSQLで検証
初めに、通常のSQLで実行した結果になります。(副問い合わせはEXISTSです)
EXPLAIN ANALYZE
SELECT
student.id AS student_id,
SUM(score) AS sum_score
FROM
student
JOIN
score
ON student.id = score.student_id
WHERE
EXISTS(
SELECT
score.subject_id
FROM
subject
WHERE
score.subject_id = subject.id
)
GROUP BY
student.id
ORDER BY
sum_score DESC;Execution Time: 4148.288 ms
Execution Time: 4020.835 ms
Execution Time: 3970.433 ms
Execution Time: 4067.576 ms
Execution Time: 4040.788 ms
平均: 4049.580ms
2.予約語は大文字にする
大文字=予約語と認識できるので可読性が高くなります。
特にWITH句を何度も繰り返しデータ加工を行うような、複雑なSQLのでは、読み直すときやレビューするときに探しやすいというメリットもあります。
オプティマイザも大文字=予約語と認識できるようにしておいた方が、解釈しやすくなり実行速度が上がるという話を聞いたことがあります。
速度の面ではどうでしょうか。
全て小文字にした場合
explain analyze
select
student.id as student_id,
sum(score) as sum_score
from
student
join
score
on student.id = score.student_id
where
exists(
select
score.subject_id
from
subject
where
score.subject_id = subject.id
)
group by
student.id
order by
sum_score desc;Execution Time: 4118.061 ms
Execution Time: 4182.103 ms
Execution Time: 4028.780 ms
Execution Time: 4098.927 ms
Execution Time: 4317.111 ms
平均: 4149.000ms
速度に大きな違いは見られませんでした。
ただし、可読性の観点から予約語は大文字にしたほうが良いと思います。
3.GROUP BY, ORDER BYで列番号ではなく列名を指定したほうが早い
列番号を指定するのは、レビューの際に可読性が悪くなるデメリットがあるので避けた方が無難です。
オプティマイザも列の名前であると一目で認識できるようにしておいた方が、解釈しやすくなり実行速度が上がるという話を聞いたことがあります。
速度の面ではどうでしょうか。
列番号を指定した場合
EXPLAIN ANALYZE
SELECT
student.id AS student_id,
SUM(score) AS sum_score
FROM
student
JOIN
score
ON student.id = score.student_id
WHERE
EXISTS(
SELECT
score.subject_id
FROM
subject
WHERE
score.subject_id = subject.id
)
GROUP BY
1
ORDER BY
2 DESC;Execution Time: 4008.868 ms
Execution Time: 4084.267 ms
Execution Time: 4045.300 ms
Execution Time: 4040.205 ms
Execution Time: 4133.155 ms
平均: 4062.360ms
こちらも速度に大きな違いは見られませんでした。
ただし、可読性の観点から列名を指定するようにしたほうが良いと思います。
4.EXISTSよりINの方が遅いという説について
案件にいた当時は、EXISTSよりINの方が遅いという話があり、私はできるだけEXISTSを使うようにしていました。
- EXISTSは、TRUEかFALSEを返して、その結果をもとに判定を行います。
- INは複数取得結果があった場合、一致するものが見つかるまで判定を繰り返します。
以上より、EXISTSは見つかった時点でTRUEを返して止まるので、INより速いと考えていました。
一方で、INとEXISTSで速度は変わらないという意見もあります。
こちらも検証してみましょう。
INで抽出した場合
EXPLAIN ANALYZE
SELECT
student.id AS student_id,
SUM(score) AS sum_score
FROM
student
JOIN
score
ON student.id = score.student_id
WHERE
subject_id IN(
SELECT
id
FROM
subject
)
GROUP BY
student.id
ORDER BY
sum_score DESC;Execution Time: 4166.796 ms
Execution Time: 3956.425 ms
Execution Time: 3982.615 ms
Execution Time: 4037.357 ms
Execution Time: 4212.102 ms
平均: 4071.060 ms
INとEXISTSで実行時間に大きな違いは見られませんでした。
5.JOINで抽出した場合
テーブルを結合して結果を集計する方法には、INやEXISTSの他にJOINがあります。
JOINで結合した場合の速度はどうでしょうか。
EXPLAIN ANALYZE
SELECT
student.id AS student_id,
SUM(score) AS sum_score
FROM
student
JOIN
score
ON student.id = score.student_id
JOIN
subject
ON subject.id = score.subject_id
GROUP BY
student.id
ORDER BY
sum_score DESC;Execution Time: 4050.662 ms
Execution Time: 4162.546 ms
Execution Time: 4118.915 ms
Execution Time: 3977.989 ms
Execution Time: 4224.440 ms
平均: 4106.91 ms
こちらも実行時間に大きな違いは見られませんでした。
6.集計関数,GROUP BY,ORDER BY,ウィンドウ関数などの対象とする列にB木(B-Tree)インデックスを貼る
以前の案件では環境の関係上インデックスを貼れなかったため、実際には行っていませんでいした。
上記の処理はいずれも重い処理ですが、B木インデックスを貼ると、内部で暗黙的にソートをしてくれるるため処理速度が速くなるそうです。
実際に、インデックスを貼った上で最初に実行したSQLとの速度を比較してみました。
実行したSQL(studentテーブルのidと、scoreテーブルのstudent_idにインデックスを貼る)
CREATE INDEX id ON student(id);
CREATE INDEX student_id_on_score ON score(student_id);※何も指定しない場合B木インデックスが適用されます。
例えば、ハッシュインデックスを指定したい場合は以下のように書きます。
CREATE INDEX id ON student USING hash (id);実行結果
「1.通常のSQLで検証」と同じSQLを使用しています。
Execution Time: 3751.164 ms
Execution Time: 3857.049 ms
Execution Time: 3978.270 ms
Execution Time: 3998.773 ms
Execution Time: 3957.869 ms
平均: 3908.63ms
劇的に早くなった・・・わけではありませんでした。
実行計画を見るとIndex Only Scan、Index Scanなどがあることから、インデックスによる検索は行われているようです。
インデックスを貼る前に実行したSQL
Sort (cost=708864.47..711361.97 rows=999000 width=12) (actual time=3977.550..4063.814 rows=967072 loops=1)
Sort Key: (sum(score.score)) DESC
Sort Method: external merge Disk: 24656kB
-> HashAggregate (cost=536156.76..592240.50 rows=999000 width=12) (actual time=3059.576..3735.534 rows=967072 loops=1)
Group Key: student.id
Planned Partitions: 32 Batches: 280 Memory Usage: 4153kB Disk Usage: 95688kB
-> Hash Join (cost=31825.08..204281.81 rows=5899999 width=8) (actual time=344.237..2378.096 rows=2946481 loops=1)
Hash Cond: (score.student_id = student.id)
-> Hash Join (cost=38.58..107010.75 rows=5899999 width=8) (actual time=112.627..1056.991 rows=2949518 loops=1)
Hash Cond: (score.subject_id = subject.id)
-> Seq Scan on score (cost=0.00..91432.99 rows=5899999 width=12) (actual time=0.074..396.429 rows=5899999 loops=1)
-> Hash (cost=22.70..22.70 rows=1270 width=4) (actual time=112.541..112.542 rows=6 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Seq Scan on subject (cost=0.00..22.70 rows=1270 width=4) (actual time=112.521..112.525 rows=6 loops=1)
-> Hash (cost=15396.00..15396.00 rows=999000 width=4) (actual time=231.264..231.265 rows=999000 loops=1)
Buckets: 131072 Batches: 16 Memory Usage: 3225kB
-> Seq Scan on student (cost=0.00..15396.00 rows=999000 width=4) (actual time=0.026..79.954 rows=999000 loops=1)
Planning Time: 0.357 ms
JIT:
Functions: 26
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 1.331 ms, Inlining 9.616 ms, Optimization 83.490 ms, Emission 52.039 ms, Total 146.476 ms
Execution Time: 4120.743 msインデックスを貼った後に実行したSQL
Sort (cost=558581.93..561079.43 rows=999000 width=12) (actual time=3710.582..3789.471 rows=967072 loops=1)
Sort Key: (sum(score.score)) DESC
Sort Method: external merge Disk: 24656kB
-> GroupAggregate (cost=7.46..441957.96 rows=999000 width=12) (actual time=117.012..3444.040 rows=967072 loops=1)
Group Key: student.id
-> Nested Loop (cost=7.46..402467.96 rows=5899999 width=8) (actual time=116.987..3112.735 rows=2946481 loops=1)
-> Merge Join (cost=7.29..255035.36 rows=5899999 width=12) (actual time=116.941..1702.304 rows=5893999 loops=1)
Merge Cond: (student.id = score.student_id)
-> Index Only Scan using id on student (cost=0.42..25964.42 rows=999000 width=4) (actual time=0.018..110.496 rows=982335 loops=1)
Heap Fetches: 295
-> Index Scan using student_id_on_score on score (cost=0.43..153304.42 rows=5899999 width=12) (actual time=0.073..852.286 rows=5899999 loops=1)
-> Memoize (cost=0.16..0.18 rows=1 width=4) (actual time=0.000..0.000 rows=0 loops=5893999)
Cache Key: score.subject_id
Cache Mode: logical
Hits: 5893987 Misses: 12 Evictions: 0 Overflows: 0 Memory Usage: 2kB
-> Index Only Scan using subject_pkey on subject (cost=0.15..0.17 rows=1 width=4) (actual time=0.003..0.003 rows=0 loops=12)
Index Cond: (id = score.subject_id)
Heap Fetches: 6
Planning Time: 0.245 ms
JIT:
Functions: 14
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 0.555 ms, Inlining 8.259 ms, Optimization 72.371 ms, Emission 36.214 ms, Total 117.399 ms
Execution Time: 3818.726 msとなると今回速度が劇的に早くならなかった理由としては、例えば、テーブルのデータがstudent.id、score.student_idで予めソートされていたから(もしも順番がバラバラであれば、B木インデックスが貼られている方が、早くなったと考えられる)が考えられそうです。
次回執筆する記事にてインデックス周りについてもっと掘り下げていきたいと思います。
補足:B木インデックスとは?
- メインとして使われるインデックスの一つ。他にはビットマップインデックス、ハッシュインデックスがある。
- 二分木構造に列データを整理することができる。つまり、昇順ソートして保持した状態になっている。
- 二分探索で探すので順探索よりもオーダが少ない。そのため範囲検索が得意で、一致検索も得意。
- 一致検索はハッシュインデックスの方が得意
- カーディナリティが低い場合はビットマップインデックスのほうが速い
- 二分探索ベースで探す関係上、否定検索、OR条件、NULL検索は不向き
7. DISTNCTを使わなくていい場面では使わない
DISTINCTは重複行を集約して処理するため、その分処理に時間がかかります。
試しに、scoreテーブルに対してDITSINCTの有無で結果を比較してみましょう。
scoreテーブルはid, student_id, subject_idで一意のデータが存在するように作っているので、どちらの場合でも取得結果は同じになります。
EXPLAIN ANALYZE SELECT DISTINCT id, student_id, subject_id, score FROM score;Execution Time: 2755.791 ms
Execution Time: 2340.919 ms
Execution Time: 2117.782 ms
Execution Time: 2112.903 ms
Execution Time: 2117.341 ms
EXPLAIN ANALYZE SELECT id, student_id, subject_id, score FROM score;Execution Time: 598.083 ms
Execution Time: 544.104 ms
Execution Time: 655.047 ms
Execution Time: 558.829 ms
Execution Time: 571.998 ms
平均値を出すまでもなく、後者の方が早いのが明らかですね。
UNIONやINTERSECTやEXCEPTなどを使う場合も、取得結果を集約をする必要がないのであれば、ALLを使ったほうが速くなるということになります。
計測結果まとめ
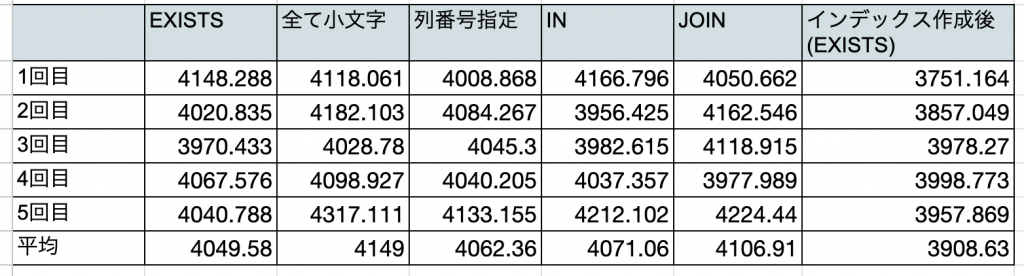
まとめ
- 予約語が大文字・小文字であるか、GROUP BYやORDER BYの指定が列名・列番号であるかは実行速度に影響しない。ただし、可読性の観点から予約語は大文字、GROUP BYやORDER BYの指定は列名にした方がいい。
- 特に必要がないなら、DISTINCTは使わない方がいい。
- IN,EXISTS,JOINで速度に大きな差異はない。
次回の記事で掘り下げたいこと
- IN,EXISTS,JOINの使い分け
- 実行速度に大きな違いはないので、技術記事やSQLの公式ドキュメントなどを読みこんで使い分けるポイントを明らかにしたい。
- インデックスの有無による速度の違い
- 今回使用作成したテスト用データをアレンジしたり、実行計画を読み解いたりして、インデックスの有無による速度への影響を明らかにしたい。
参考資料
dockerでPostgresSQLとpgAdminの環境を構築する方法
https://qiita.com/Akhr/items/8d5b5127ee971a640253
SQL高速化のコツ
https://style.potepan.com/articles/26070.html
テスト用に大量のデータを作成する方法
https://qiita.com/cobot00/items/8d59e0734314a88d74c7
プロフィール

-
新卒でSIerに入社し、その後メンバーズに転職。
フロント案件を主に経験していたが、インフラ周りのスキルを身につけたいという思いから社内公募制度を利用し、2022年12月に異動。
最新の投稿
 ナレッジ2023.09.22SQL速度向上のために過去に自分が意識していた書き方の効果を実際に検証してみた
ナレッジ2023.09.22SQL速度向上のために過去に自分が意識していた書き方の効果を実際に検証してみた ナレッジ2023.09.01jsonファイルをjqで絞り込んでS3に送信するGithub Actionsワークフローを作ってみた
ナレッジ2023.09.01jsonファイルをjqで絞り込んでS3に送信するGithub Actionsワークフローを作ってみた ナレッジ2023.08.18VSCodeにlinterとformatterを入れて生産性・品質向上
ナレッジ2023.08.18VSCodeにlinterとformatterを入れて生産性・品質向上 ナレッジ2023.08.04二分木の直径を求める問題を幅優先探索で解いてみる
ナレッジ2023.08.04二分木の直径を求める問題を幅優先探索で解いてみる