



先日、業務でGithub Actionsでデプロイするワークフローを作成する作業を経験しました。 Github Actionsもjqも未経験な上、記法が独特で苦戦することが多々ありました。
その経験から学習のために「設定した条件に基づいてjsonファイルを絞り込んで、S3に送るGithub Actionsのワークフロー」を作成してみました。
構成
プロジェクトフォルダ
├── era_data
│ └── kamakura_early_era_data.json
└── .github
└── workflows
└── deploy.yml概要
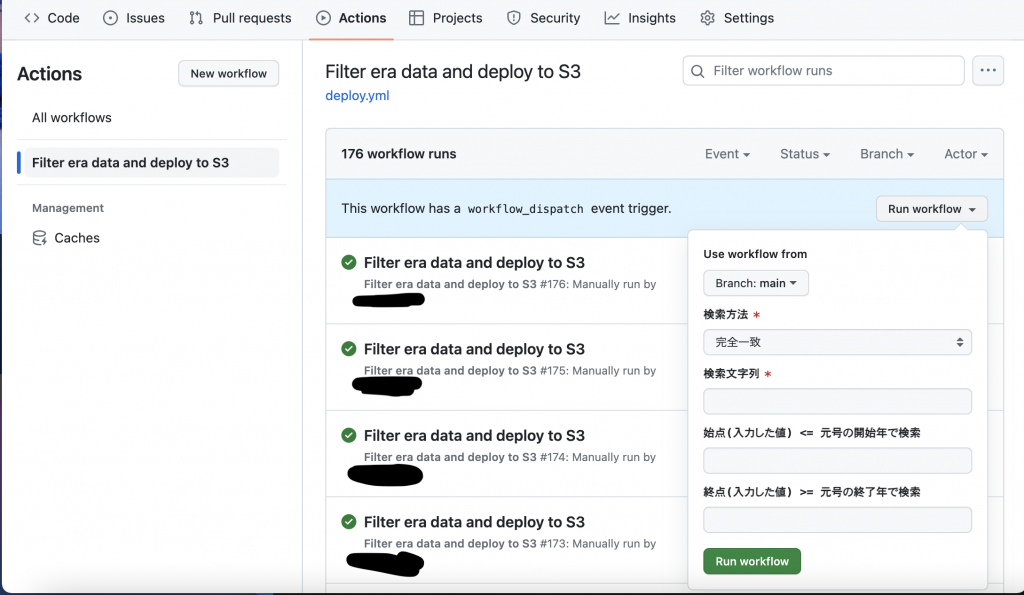
Github Actionsの画面でrun workflowを選択し、条件を入力すると条件に基づきkamakura_early_era_data.jsonのデータを絞り込んで、S3に送信します。
ファイルについて
kamakura_early_era_data.json
鎌倉時代初期の元号をJSON配列形式で格納しています。
[
{
"id": 106,
"name": "元暦",
"start": 1184,
"end": 1185
},
{
"id": 107,
"name": "文治",
"start": 1185,
"end": 1190
},
{
"id": 108,
"name": "建久",
"start": 1190,
"end": 1199
},
{
"id": 109,
"name": "正治",
"start": 1199,
"end": 1201
},
{
"id": 110,
"name": "建仁",
"start": 1201,
"end": 1204
},
{
"id": 111,
"name": "元久",
"start": 1204,
"end": 1206
},
{
"id": 112,
"name": "建永",
"start": 1206,
"end": 1207
},
{
"id": 113,
"name": "承元",
"start": 1207,
"end": 1211
},
{
"id": 114,
"name": "建暦",
"start": 1211,
"end": 1213
},
{
"id": 115,
"name": "建保",
"start": 1213,
"end": 1219
},
{
"id": 115,
"name": "承久",
"start": 1219,
"end": 1222
}
].github/workflows/deploy.yml
name: Filter era data and deploy to S3
on:
workflow_dispatch:
inputs:
search_type:
type: choice
required: true
description: 検索方法
options:
- 完全一致
- 前方一致
- 後方一致
- 正規表現一致
pattern:
type: string
required: true
description: 検索文字列
start_year:
type: number
description: 始点(入力した値) <= 元号の開始年で検索
end_year:
type: number
description: 終点(入力した値) >= 元号の終了年で検索
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
# 検索条件を出力する
- name: echo
run:
echo "search_type ${{ github.event.inputs.search_type }}"
echo "pattern ${{ github.event.inputs.pattern }}"
echo "start_year ${{ github.event.inputs.start_year }}"
echo "end_year ${{ github.event.inputs.end_year }}"
# 検索方法に応じて分岐する
# 完全一致
- name: Get era data by perfect matching
if: ${{ github.event.inputs.search_type == vars.PERFECT_MATCH }}
run: |
data=$(
cat era_data/kamakura_early_era_data.json |
jq 'map(select( .["name"] == "${{ inputs.pattern }}"))'
)
echo "value="$data > $GITHUB_ENV
# 前方一致
- name: Get era data by first half match
if: ${{ github.event.inputs.search_type == vars.FIRST_HALF_MATCH }}
run: |
data=$(
cat era_data/kamakura_early_era_data.json |
jq '[
.[] | select(.name | startswith("${{ inputs.pattern }}"))
']
)
echo "value="$data > $GITHUB_ENV
# 後方一致
- name: Get era data by second half match
if: ${{ github.event.inputs.search_type == vars.SECOND_HALF_MATCH }}
run: |
data=$(
cat era_data/kamakura_early_era_data.json |
jq '[
.[] | select(.name | endswith("${{ inputs.pattern }}"))
']
)
echo "value="$data > $GITHUB_ENV
# 正規表現
- name: Get era data by regex
if: ${{ github.event.inputs.search_type == vars.REGEX_MATCH }}
run: |
data=$(
cat era_data/kamakura_early_era_data.json |
jq '[
.[] | select(.name | test("${{ inputs.pattern }}"))
']
)
echo "value="$data > $GITHUB_ENV
# 入力した開始年、終了年で絞り込む
# 始点(入力した値) <= 元号の開始年で検索
- name: Filter by start year
if: github.event.inputs.start_year != '' && env.value != ''
run: |
data=$(
echo '${{ env.value }}' |
jq '[
.[] | select(.start >= ${{ inputs.start_year }})
']
)
echo "value="$data >> $GITHUB_ENV
# 終点(入力した値) >= 元号の終了年で検索
- name: Filter by end year
if: github.event.inputs.end_year != '' && env.value != ''
run: |
data=$(
echo '${{ env.value }}' |
jq '[
.[] | select(.end <= ${{ inputs.end_year }})
']
)
echo "value="$data >> $GITHUB_ENV
# Jsonファイルに書き込む
- name: Update Json File
run: |
echo ${{ env.value }} > era_data/kamakura_era.json
# JsonファイルをS3に送る
- name: Deploy to S3
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
aws s3 sync --delete --region ap-northeast-1 ./era_data/ ${{ secrets.S3_NAME }}ワークフローの処理について
概要
- inputsで選んだ検索方法、検索文字列、始点、終点で絞りこみます
- 検索方法はリストから選択する形式
- 検索方法、検索文字列は必須入力
- はじめに、選択した条件と入力した文字列に基づき絞り込みを行います(完全一致、前方一致、後方一致、正規表現)
- 結果を環境変数として$GITHUB_ENVにenv.valueとして書き込みます
- 次に、始点(入力した値) <= 元号の開始年、終点(入力した値) >= 元号の終了年、で絞り込みます
- それぞれ個別に絞り込み処理を実行します
- 任意入力なので、未入力の場合処理を実行しません
- env.valueが空の場合も実行しません
- 最終的にenv.valueの値をera_data/kamakura_era.jsonに書き込みます
- era_data/kamakura_era.jsonをs3 syncコマンドで転送します
Inputsについて
- choiceにすると選択肢形式にできます
- Requiredをtrueにすると入力必須にできます
- ${{ github.event.inputs.id }}で参照可能
- $ {{}}はコンテキストにアクセスするのに使う式構文。if文内では${{}}なしでアクセスできます
- 参考1 https://docs.github.com/ja/actions/learn-github-actions/contexts#about-contexts
- 参考2 https://docs.github.com/ja/actions/learn-github-actions/expressions#about-expressions
jqについて
data=$(
cat era_data/kamakura_early_era_data.json |
jq '[
.[] | select(.name | startswith("${{ inputs.pattern }}"))
']
)
echo "value="$data > $GITHUB_ENV上の処理で行っている処理の解説をします。 (実際にファイルをディレクトリに作成して、コマンドを打ってみるとデータの加工の流れがイメージしやすいです)
1.catでjsonファイルの中身を出力します。
cat era_data/kamakura_early_era_data.json
[
{
"id": 106,
"name": "元暦",
"start": 1184,
"end": 1185
},
(中略)
{
"id": 115,
"name": "承久",
"start": 1219,
"end": 1222
}
]%↓ 2.パイプでjqに渡します。 まず.[]で配列を展開します。
cat era_data/kamakura_early_era_data.json | jq '.[]'
{
"id": 106,
"name": "元暦",
"start": 1184,
"end": 1185
}
(中略)
{
"id": 115,
"name": "承久",
"start": 1219,
"end": 1222
}↓ 3.展開したjsonを条件で絞り込みます。
cat era_data/kamakura_early_era_data.json | jq '.[] | select(.name | startswith("建"))'
{
"id": 108,
"name": "建久",
"start": 1190,
"end": 1199
}
{
"id": 110,
"name": "建仁",
"start": 1201,
"end": 1204
}
{
"id": 112,
"name": "建永",
"start": 1206,
"end": 1207
}
{
"id": 114,
"name": "建暦",
"start": 1211,
"end": 1213
}
{
"id": 115,
"name": "建保",
"start": 1213,
"end": 1219
}↓ 4.最後にjq処理がかかる箇所全体を\'[]\'で囲んで配列化します。
cat era_data/kamakura_early_era_data.json | jq '[.[] | select(.name | startswith("建"))]'
[
{
"id": 108,
"name": "建久",
"start": 1190,
"end": 1199
},
{
"id": 110,
"name": "建仁",
"start": 1201,
"end": 1204
},
{
"id": 112,
"name": "建永",
"start": 1206,
"end": 1207
},
{
"id": 114,
"name": "建暦",
"start": 1211,
"end": 1213
},
{
"id": 115,
"name": "建保",
"start": 1213,
"end": 1219
}
]echo "value="$data > $GITHUB_ENVについて
$GITHUB_ENVという環境ファイルに変数を書き込む処理をしています。 後続の処理で、式構文を使って参照ができるようになっています。 今回の場合は${{env.value}}で参照できます。
$GITHUB_OUTPUTを介して、前のステップの値を参照することもできます。 しかし、今回のケースでは始点、終点の入力の有無によって最後に変数に書き込みが行われる箇所が変わるため、$GITHUB_ENVを使用しています。
もし$GITHUB_OUTPUTを使う場合は以下のような書き方ができます。 ###で記載している箇所が変更箇所になります。
# 終点(入力した値) >= 元号の終了年で検索
- name: Filter by end year
id: filter-by-end-year ###idを設定します。
if: github.event.inputs.end_year != '' && env.value != ''
run: |
data=$(
echo '${{ env.value }}' |
jq '[
.[] | select(.end <= ${{ inputs.end_year }})
']
)
echo "value="$data >> $GITHUB_OUTPUT ###GITHUB_OUTPUTに出力します。
# Jsonファイルに書き込む
- name: Update Json File
run: |
echo ${{ env.value }} > era_data/kamakura_era.json
echo ${{ steps.filter-by-end-year.outputs.value }} ###idを介してGITHUB_OUTPUTにアクセスします。varsとsecrets
Settings > secrets and variables > Actions より、Secretsとvariablesでそれぞれ定数を定義することができます。 ワークフローの処理中で使う定数など見られてもセキュリティ上の問題がないものはvariablesに定義して、${{vars.PERFECT_MATCH}}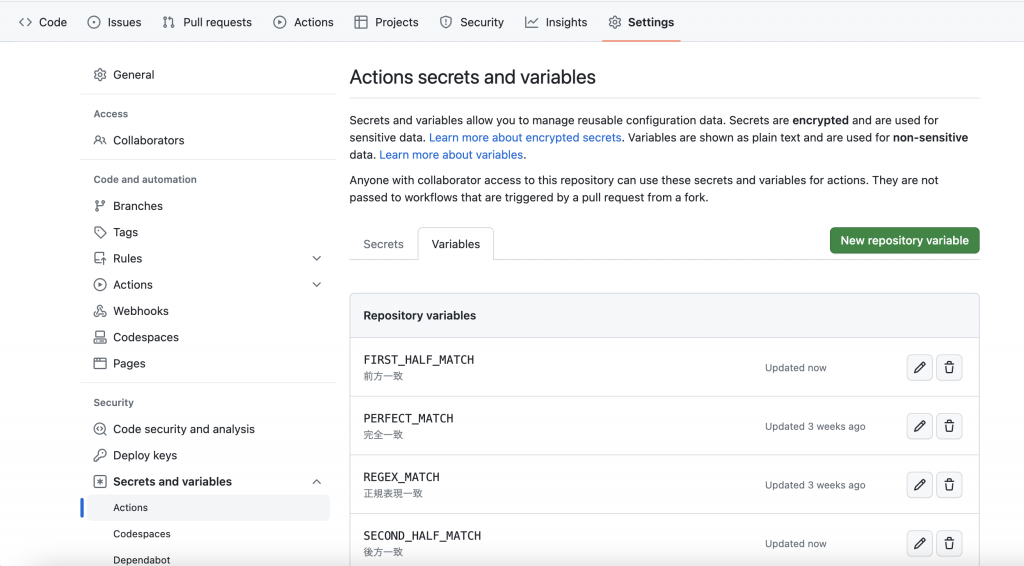
AWSのアクセスキーやS3バケット名など見られたくない値は、secretsに定義して、${{ secrets.S3_NAME }}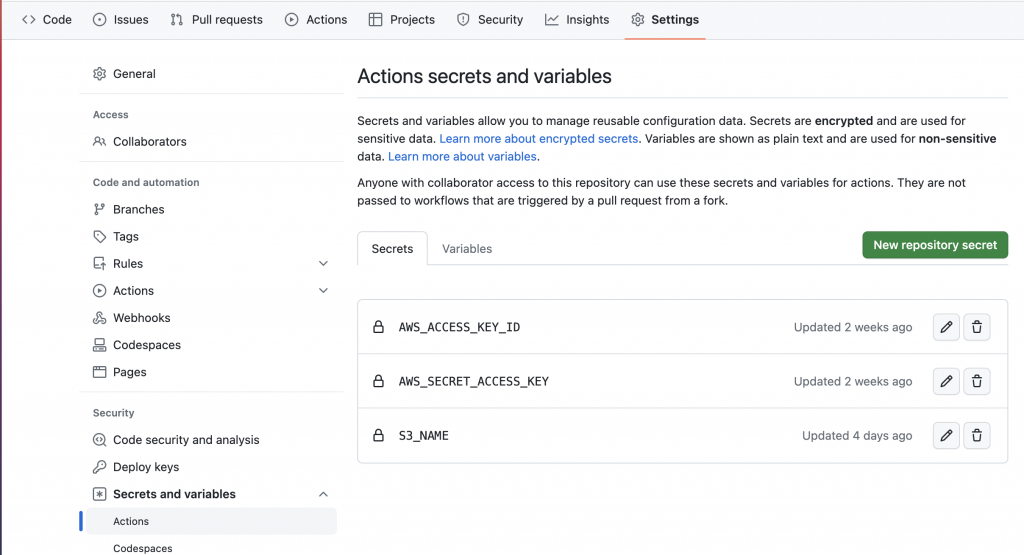
実際に実行した結果
設定した条件
完全一致 建久 (空白) (空白)
前方一致 建 (空白) (空白)
前方一致 建 1202 1212
後方一致 久 (空白) (空白)
後方一致 久 1199 1223
正規表現一致 .*[建|久].* (空白) (空白)
前方一致 建 1000 (空白)
前方一致 建 2000 (空白)
前方一致 建 (空白) 1000
前方一致 令 (空白) 2000実行結果

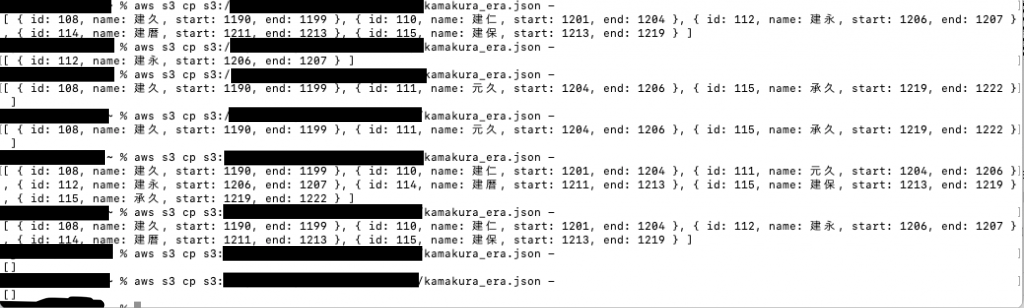
Github Actionsのワークフロー実行履歴でも正常に終了しているのを確認できました。 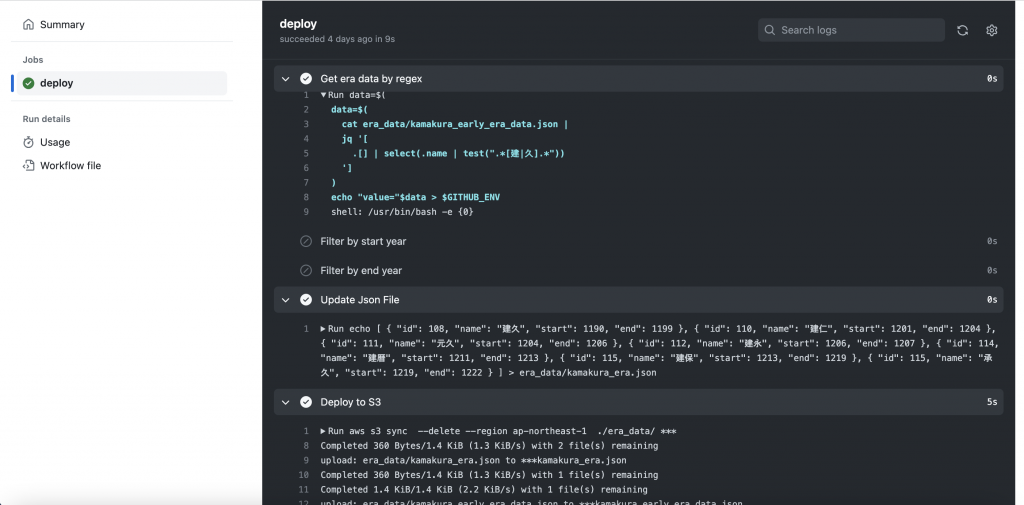
学んだこと
- jqは記法がとっつきにくいですが、一つ一つの処理に分解して考えるのと、実際にコマンドを打って確認することで理解しやすくなります。
- コーテーション、パイプ、括弧を多用するので囲んでいる範囲がわからなくならないよう適宜フォーマットするのが大事。
- Github Actionsはとても便利。ワークフローを実行するだけでデータを加工したり、ビルドしたりした上で、S3などの外部サービスにデータを転送する、というような使い方ができる。もっとCIツールを学んでみたい。
プロフィール

-
新卒でSIerに入社し、その後メンバーズに転職。
フロント案件を主に経験していたが、インフラ周りのスキルを身につけたいという思いから社内公募制度を利用し、2022年12月に異動。
最新の投稿
 ナレッジ2023.09.22SQL速度向上のために過去に自分が意識していた書き方の効果を実際に検証してみた
ナレッジ2023.09.22SQL速度向上のために過去に自分が意識していた書き方の効果を実際に検証してみた ナレッジ2023.09.01jsonファイルをjqで絞り込んでS3に送信するGithub Actionsワークフローを作ってみた
ナレッジ2023.09.01jsonファイルをjqで絞り込んでS3に送信するGithub Actionsワークフローを作ってみた ナレッジ2023.08.18VSCodeにlinterとformatterを入れて生産性・品質向上
ナレッジ2023.08.18VSCodeにlinterとformatterを入れて生産性・品質向上 ナレッジ2023.08.04二分木の直径を求める問題を幅優先探索で解いてみる
ナレッジ2023.08.04二分木の直径を求める問題を幅優先探索で解いてみる